Rich feature hierarchies for accurate object detection and semantic segmentation
<논문리뷰> R-CNN에 대하여
Abstract
본 논문에서는 VOC 2012에서 이전 최고 성과보다 mAP(평균 정밀도)를 30% 이상 개선해 53.3%를 달성하여 cnn localization 문제를 해결하는 detection algorithm을 제안한다.
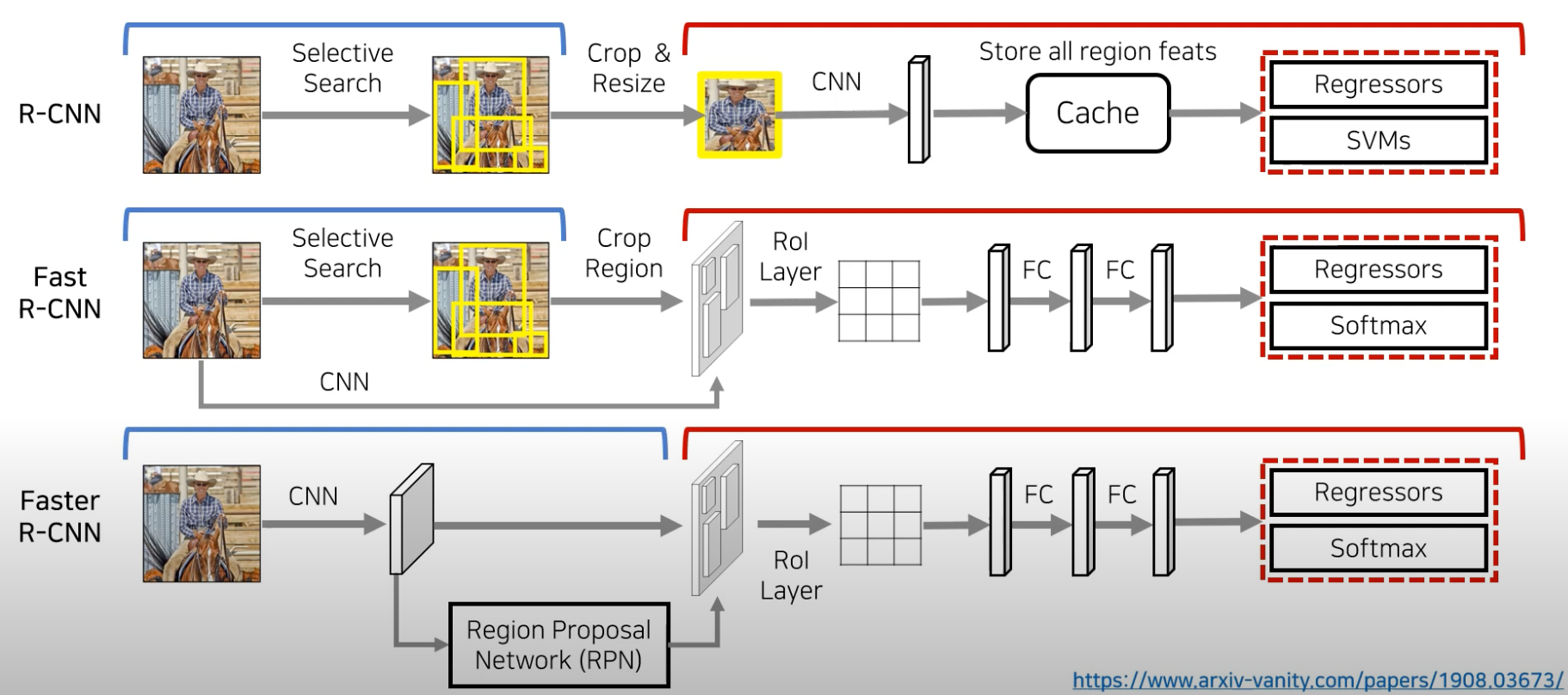
region proposals with CNNs의 과정을 일컫는 ‘R-CCN’은 localization → classification을 순차적으로 진행하는 ‘2 stage detector’의 근간이 되는 모델로 아래와 같은 특징이 존재한다.
- Two key insights
- bottom-up region proposals에 고성능의 CNN을 적용해 객체를 localize & segment 할 수 있다.
- labeled training data가 scarce할 때, 보조 작업에 대해 supervise pre-training을 수행한 후 domain-specific fine-tuning을 하면 성능이 크게 향상된다.
- 전반적 과정은 아래와 같다.
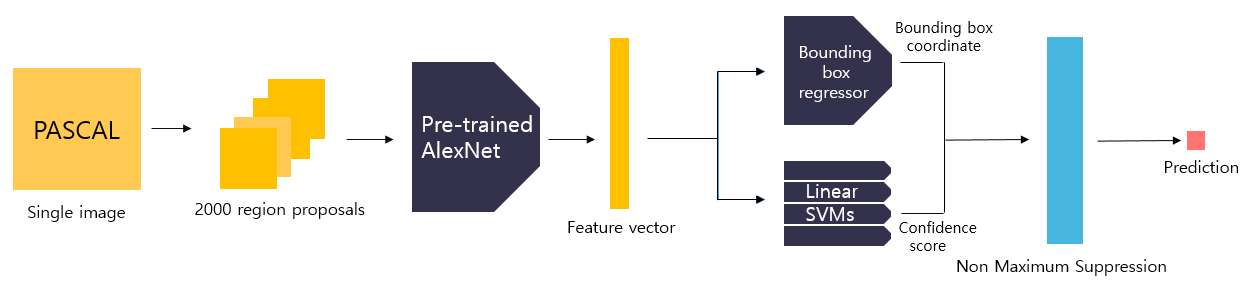
- Selective search 알고리즘을 이용해 2,000개의 region proposals을 추출한다.
- 각 RoI에 대해 warping을 수행해 227x227 크기의 입력이미지로 변경시켜준다.
- Warped image를 Fine-Tuning된 AlexNet에 넣어서 forward propagation을 수행해 feature vector를 추출한다.
- 해당 feature를 linear SVM 모델과 Bounding box regressor 모델에 넣어 클래스 분류 결과를 얻는다.
- non-maximum suppression 알고리즘을 적용해 최적의 bounding box를 예측한다.
 [Object detection system overview]
[Object detection system overview]
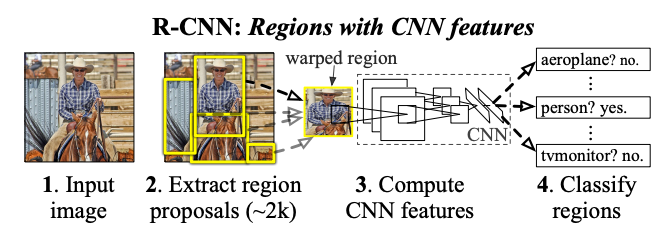
 Object detection by R-CNN
Object detection by R-CNN
Object detection with R-CNN
R-CNN의 모듈은 3개로 구성되어 있다.
- Region Proposals: detector가 탐지할 수 있는 영역 후보 set
- CNN: 각 region에서 고정된 크기의 feature vector를 추출(AlexNet)
- Linear SVMs: 클래스별 분류 진행
Module design
- Region proposals
objectness, selective search, category-independent object proposals, CPMC, multi-scale combinatorial grouping, Ciresan와 같이 category-independent region proposals를 생성하는 method가 이전 여러 논문에서 제안되었다.
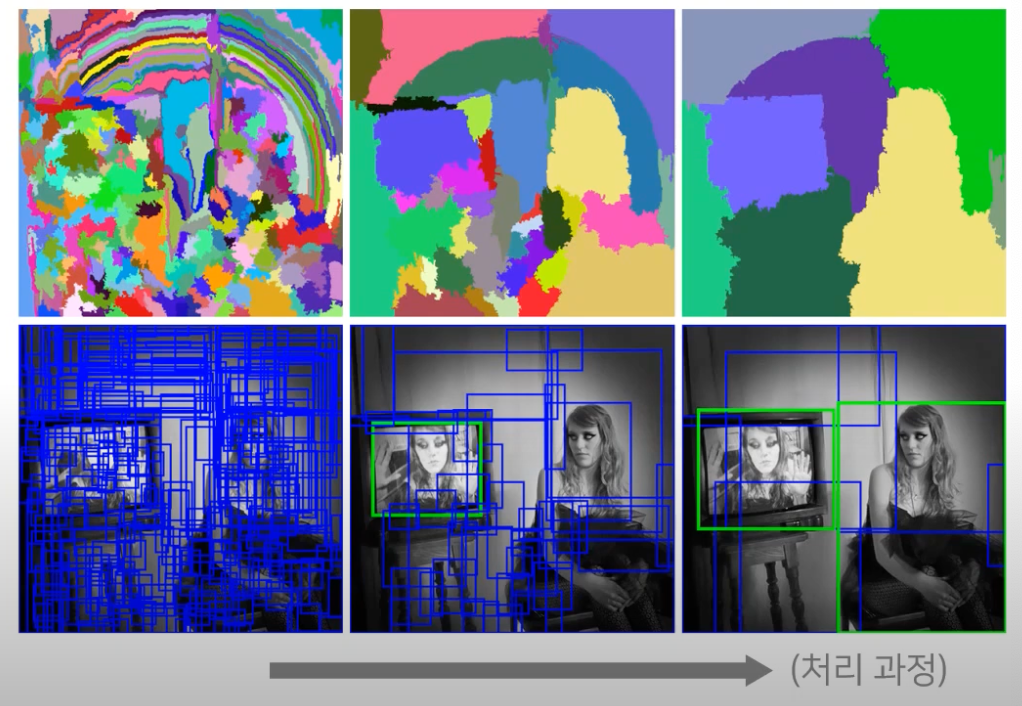
본 논문에서는, 이전 연구와의 비교를 위해 ‘selective search’를 사용하였다.
Selective Search: 인접한 영역끼리 유사성을 측정해 큰 영역으로 차례대로 통합해 나가는 과정(R-CNN/ Fast R-CNN)
→ Bottom-up 방식으로 non-objective segmentation으로 수행된 small segmented areas를 합쳐서 더 큰 segmented areas를 만드는 과정을 반복하여 최종적으로 2,000개의 region proposal을 생성한다.
- Feature extraction
- CNN 구조는 고정된 227x227 pixel size의 입력을 요구한다. 따라서 얻은 2,000장의 Region proposals을 warping하는 과정을 수행한다.
본 논문에서는 tight bounding box를 확장하여 변형된 크기에서 original box 주변에 p pixel(p = 16)의 warped image context가 포함되도록 하여 배경을 살리고 해당 영역 주변의 모든 pixel을 필요한 크기로 warping한다.
 (D)가 warping한 버전 / 각 사진 set 아래 행: padding size = 16 적용한 버전
(D)가 warping한 버전 / 각 사진 set 아래 행: padding size = 16 적용한 버전Domain-specific fine-tuning
Pre-trained된 AlexNet을 가져와서 마지막 단의 Linear Layer의 출력 클래스 개수만 데이터 셋에 맞게 바꾼 뒤, 모델을 파인튜닝 시키는데 이때, input에 들어온 region proposal은 객체 or 배경을 포함하고 있을 수 있다.
추출한 bounding box와 ground truth box와의 IoU(Intersection over Union) overlap 값을 구하여 아래와 같이 예제를 저장한다.
- positive sample(객체): IoU ≥ 0.5
- negative sample(배경): IoU < 0.5
따라서 각 SGD 반복에서 모든 클래스에 걸쳐 32개의 positive windows과 96개의 background windows을 균일하게 샘플링하여 mini batch(=128)를 구성해 pre-trained AlexNet에 입력하여 학습을 진행시킨다.
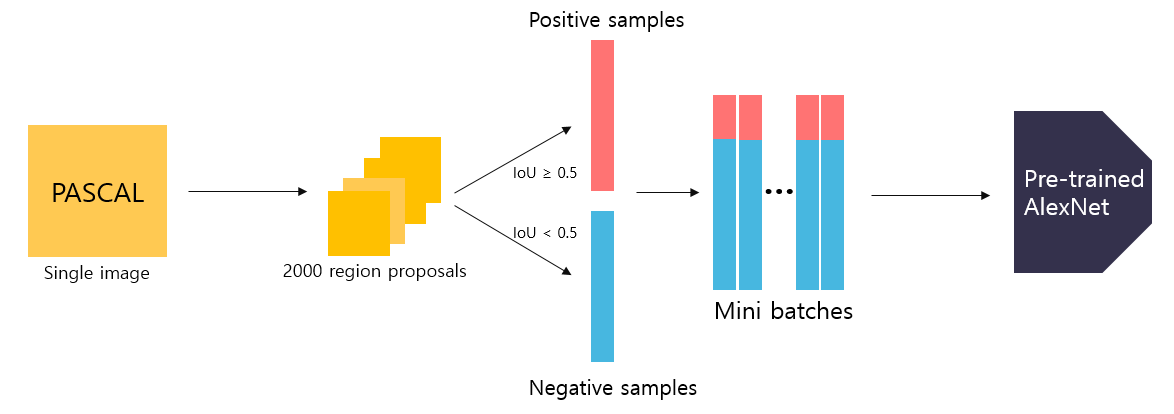 Domain-specific fine-tuning
Domain-specific fine-tuning
Linear SVMs(Support Vector Machines)
입력받은 2000(개수)x4096(차원) feature vector의 class를 예측하고 confidence score를 반환할 때, 결과는 binary classifier이기 때문에 N개의 class를 예측할 때 배경을 포함한 (N+1)개의 linear SVM 모델을 학습시켜야 한다.
(For PASCAL VOC: N = 20→21, For ILSVRC 2013: N = 200→2001)
CNN을 fine-tuning할 때는 IoU 값 0.5를 기준으로 객체와 배경을 labeling했지만 SVM을 학습할 때는 0.3을 기준으로 하였다.
- positive example: ground truth boxes
- negative example: IoU < 0.3
이렇게 한 차례의 학습이 끝나면 추출된 false positive sample들을 epoch마다 학습 데이터에 추가하여 학습을 진행시키는 hard negative mining을 적용하여 robust한 모델을 만들기 위해 재학습시킨다.
Bounding-box regression
Selective search 알고리즘을 통해 얻은 객체의 위치는 다소 부정확할 수 있기 때문에 이러한 location error를 줄이기 위해 bounding box의 좌표를 변환해 객체의 위치를 세밀하게 조정해주는 Bounding box regressor 모델을 사용했다.
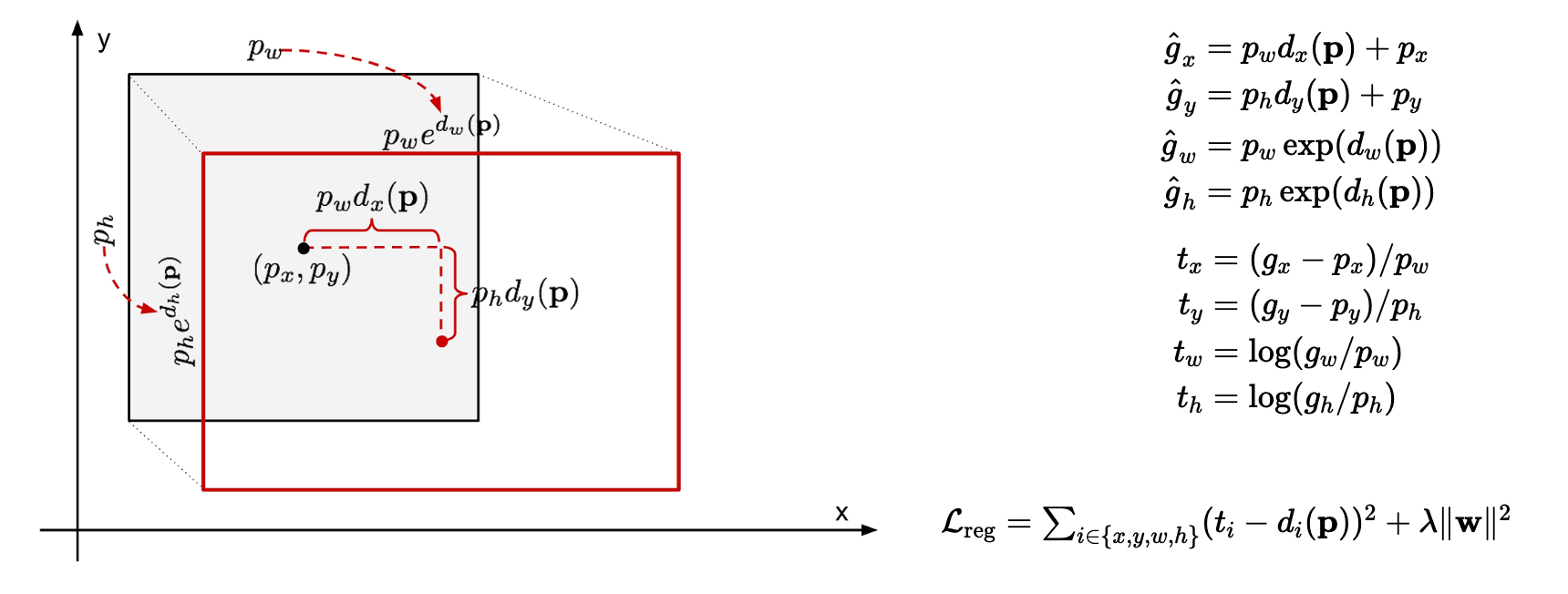 gray box: Selective search에 의해 예측된 bounding box, red box: ground truth box
gray box: Selective search에 의해 예측된 bounding box, red box: ground truth box
- 예측한 bounding box 좌표 $P = (p_x, p_y, p_w, p_h)$(x,y는 center)가 주어졌을 때 ground truth box 좌표 $g = (gx, gy, gw, gh)$로 변환되도록 하는 Scale invariant Transformation을 학습한다.
- i ∈ {x, y, w, h} 일 때, 변수는 다음과 같다.
- $\hat{g}_i$: 예측한 bounding box p가 주어졌을 때, Bounding box regressor 모델이 변환한 결과
- $t_i$: Bounding box regressor 모델의 target
- $d_i(P)$: Bounding box regressor 모델의 학습 대상
- cnn에서 추출된 feature vector를 사용해 함수에 weight vector를 주어 계산한다.
- $d_{\text{i}}(P) = \mathbf{w}_{\text{i}}^T \phi_5(P)$
- $L_{reg}$: Bounding box regressor 모델의 loss function으로 SSE(Sum of Squared Error), 본 논문에서는 λ=1000
즉, Bounding box regressor은 모델의 학습대상 $d_i(P)$이 목표 $t_i$와 가까워진도록 loss function을 통해 학습시킨다.
Non maximum Suppression(NMS)
Linear SVMs, Bounding box regressor 모델을 통해 얻은 2000개의 bounding box는 하나의 객체에 지나치게 많은 box가 겹칠 수 있기 때문에 가장 적합한 box를 선택하는 Non maximum suppression 알고리즘을 적용했다.
- 클래스별로 학습된 임계값(threshold)보다 더 높은 IoU overlap을 가진 영역이 있는 경우 해당 영역을 제거한다.
남은 bounding box를 내림차순 정렬하고 그 다음 IoU 값을 조사하여 IoU threshold 이상인 box를 모두 제거하는 과정을 반복한다.
따라서, 최종적으로 남아있는 box만 선택한다.
- 즉, 이 알고리즘은 confidense score threshold가 높을수록, IoU threshold가 낮을수록 많은 box가 제거되어 최적의 bounding box가 반환된다.
Results
PASCAL VOC 2010-12
 VOC 2010 test에서의 detection 평균 정밀도: selective search를 사용하는 UVA & Regionlets와 비교
VOC 2010 test에서의 detection 평균 정밀도: selective search를 사용하는 UVA & Regionlets와 비교ILSVRC2013 detection
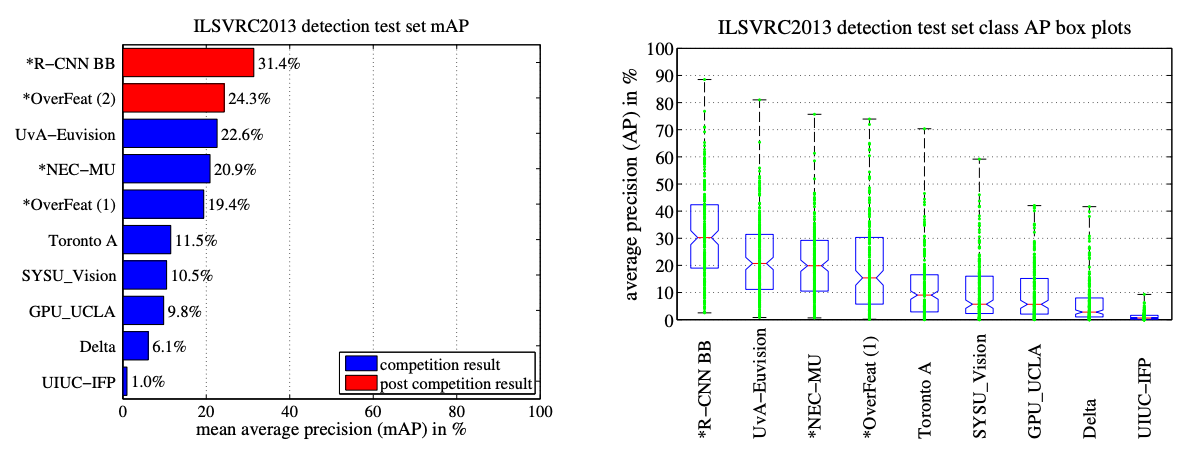 ILSVRC2013 test set에서의 mAP / method별 200개의 평균 정밀도 값에 대한 Box plots
ILSVRC2013 test set에서의 mAP / method별 200개의 평균 정밀도 값에 대한 Box plots
Qualitative results
각 이미지는 $val_2$ set에서 무작위로 샘플링되었으며, 정밀도가 0.5보다 큰 모든 검출기의 결과가 표시되었다.
 ‘not’ curated examples
‘not’ curated examples
 Curated examples
Curated examples
Conclusion
R-CNN은 2-stage detector의 대표적인 R-CNN 계열의 시초가 되는 모델으로써 풍부한 데이터가 있는 ‘auxiliary task’ 작업에 대해 supervision으로 네트워크를 사전학습한 후, 데이터가 부족한 ‘target task’에 대해 네트워크를 Fine-tuning 하는 것이 매우 효과적임을 보여주며 당시 초기의 detection 영역에서 우수한 성능을 달성하였다.
그러나 아래와 같은 한계점이 존재했다.
- 입력 이미지에 대해 CPU 기반의 ‘Selective Search’를 진행해야 하므로 많은 시간이 소요된다. ⇒ Training Time: 84h, Testing Time: 13s per frame(GPU K40)
- 전체 아키텍처에서 SVM, Regressor 모듈이 CNN과 분리되어 있다. 따라서, SVM과 Bounding Box Regression 결과로 end-to-end 방식으로 CNN을 업데이트할 수 없다.
- 모든 RoI를 CNN에 넣어야 하기 때문에 매우 많은 연산을 필요로 한다.(논문에서는 2,000번) 다시말해, 학습과 평과 과정에서 많은 시간이 필요하다.
이후 위 한계점들을 수정, 보완하여 성능과 속도를 향상시킨 Fast R-CNN → Faster R-CNN이 등장하였다.