Densely Connected Convolutional Networks
<논문리뷰> ResNets과 DenseNets에 대하여
Summary
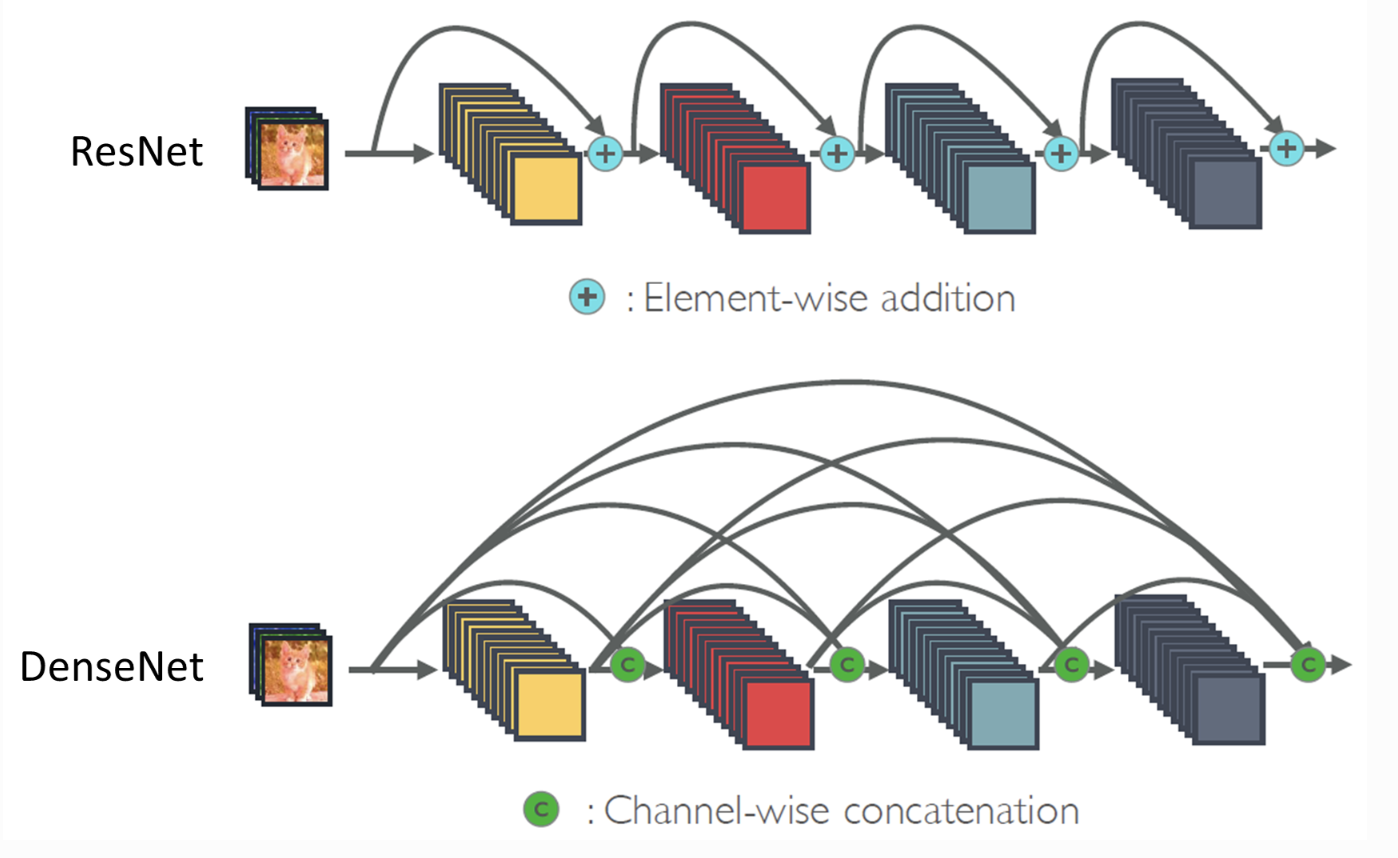
- DenseNet은 각 층을 모든 이전 층과 연결하는 feed-forward 방식을 ‘concatenation’을 사용해 깊고 효율적인 네트워크를 구축한다.
층 사이에 $\frac{L(L+1)}{2}$개의 direct connections을 가지며, 각 층에 대해 모든 이전 층의 feature-map이 입력으로 사용된다.
→ vanishing-gradient 문제 해결, feature propagation, feature reuse, 적은 파라미터로 좋은 성능을 낼 수 있다.
Introduction
입력 정보나 기울기가 깊은 여러 층을 통과할 때 네트워크의 끝이나 시작에서 사라지거나 희미해질 수 있다. 따라서 ResNets은 identity connections를 사용해 Stochastic Depth layers을 무작위로 drop하여 정보와 기울기 흐름을 개선한다.
- ResNet이란?
skip-connection
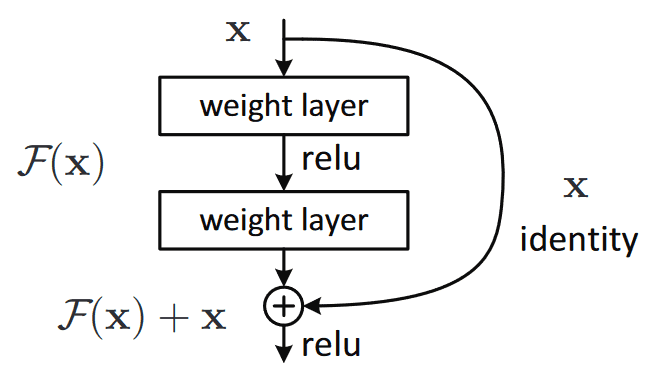
x가 들어와 F(x)가 나가는게 기존 방식이라면, x+F(x)가 나가게끔 연결해주는게 skip-connection이다. 하나의 layer를 지날 때 값의 변화가 그리 크지 않을테니 즉, $H(x) \approx x$ 일 테니 layer를 조금씩 바꿔나간다. 이는 변화량만을 학습하기 때문에 학습이 쉽다.
3 → 3.1이 될 때 x → F(x)가 아닌, F(x)+x 가 된다. 즉 3 + 0.1 → 3.1 이 된다.
하지만, ResNets은 additive identity transformations을 통해 전달된 많은 층이 매우 적은 기여를 하고 훈련 중 무작위로 삭제될 수 있으며, 각 층이 고유한 가중치를 가지기 때문에 파라미터 수가 굉장히 많다.
본 논문에서는 이 문제를 해결하기 위해 ResNet과 같은 구조 내에 $H_{\ell}(\cdot)$에 대한 입력을 합산(summatioin)하는 대신 concatenation하여 네트워크 내 층 사이의 maximum information flow를 보장한다.
DenseNets
: 단일 이미지 $x_0$가 있을 때, 이 네트워크는 L개의 층으로 각 층은 $H_{\ell}(\cdot)$라는 비선형 변환($\ell$ = layer)을 구현한다.
$H_{\ell}(\cdot)$는 Batch Normalization(BN), ReLU, Pooling, or Conv와 같은 연산들의 합성함수로, $\ell$번째 층의 출력을 $x_{\ell}$로 나타낸다.
ResNets connectivity
$\ell$번째 층의 출력을 $(\ell+1)$번째 층의 입력으로 연결해
$x_{\ell} = H_{\ell}(x_{\ell-1})$ 와 같은 층 전이가 발생한다. 여기서 ResNets은 비선형변환을 identity function로 우회하는 skip-connection을 추가한다.
ResNet의 H(): convolution → BN → ReLU
\[x_{\ell} = H_{\ell}(x_{\ell-1}) + x_{\ell-1}\]→ intentity function과 $H_{\ell}$의 출력은 덧셈에 의해 결합되어 네트워크 내 information flow을 방해할 수 있다.
DenseNets connectivity
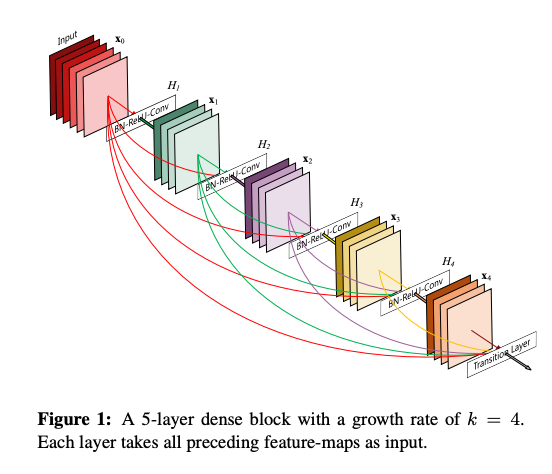
층간 정보 흐름을 더욱 향상시키기 위해, DenseNet은 모든 층에서 모든 이후 층으로 direct connections을 도입했다. DenseNet의 $\ell$번째 층은 모든 이전 층의 0에서 $\ell-1$까지 생성된 feature-maps들의 연결을 입력으로 받는다.
DenseNet의 H(): BN → ReLU → 3x3 conv
\[x_{\ell} = H_{\ell}([x_0, x_1, \dots, x_{\ell-1}])\]→ pre-activation: cnn 연산 전 activation function 연산
 $l^{th}$층은 $l$개의 input, 자신의 feature map은 모든 $l-1$ 이후 층에 전달된다.따라서, $\frac{L(L+1)}{2}$개의 연결을 도입한다.
$l^{th}$층은 $l$개의 input, 자신의 feature map은 모든 $l-1$ 이후 층에 전달된다.따라서, $\frac{L(L+1)}{2}$개의 연결을 도입한다.
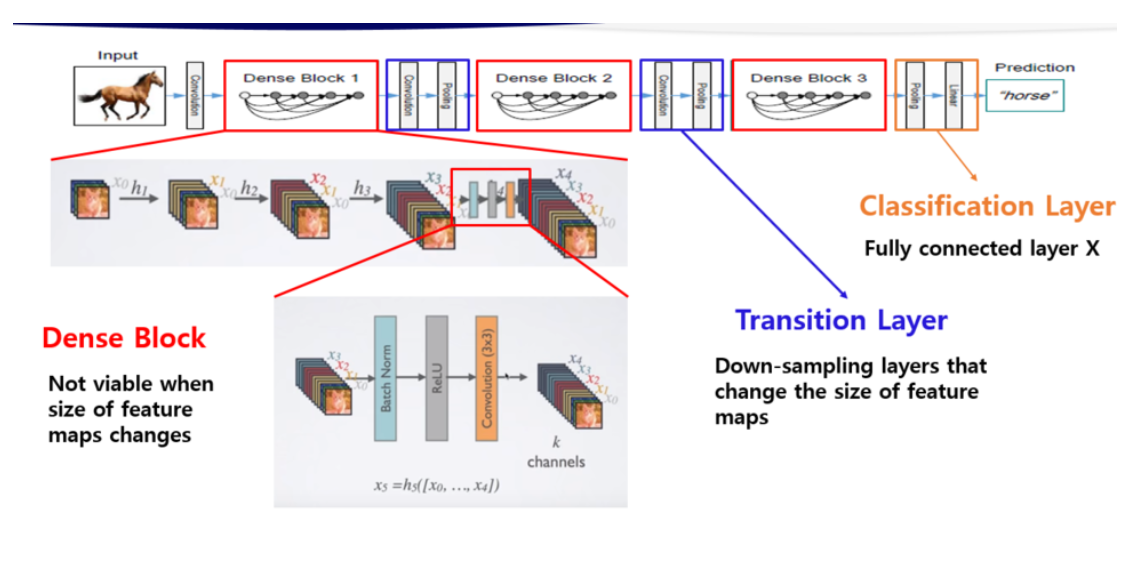
Dense block
feature map의 크기를 변경하는 down-sampling을 하기 위해 네트워크를 여러개의 dense blocks로 나눈다.
Transition Layer
batch normalization layer, 1x1 convolutional layer, 2x2 average pooling layer로 이루어져 있는 층으로 conv, pooling을 수행하여 Dense block간의 층을 연결한다.
Growth rate
DenseNet에서 concatenate를 할 때 각 layer에서의 output을 똑같은 채널 수로 만들어 줘야 하는데 이때 Dense Block 내의 layer는 k개의 feature map을 생성하고 이때의 k를 Growth rate라 정의한다.
만약 어떤 layer 이후의 모든 layer들을 전부 concatenation하면 feature의 갯수가 늘어나게 되므로 growth rate라는 값을 통해 일정하게 등차수열의 형태로 channel 수가 늘어나게 되면 feature 수가 늘어나는 것을 조절할 수 있다.
각 함수 $H_{\ell}$이 k개의 feature-map을 생성할 때, $\ell$번째 층은 $k_0 + k \times (\ell-1)$개의 Input feature-maps를 가지게 된다.
input Layer 수
conv 1 input channel: 6 → conv 2 input channel: 6+4 = 10 → conv 3 input channel: 6+4+4 = 14 → conv 4 input channel: 6+4+4+4 = 18
→ Transition Layer input channel: 6+4+4+4+4 = 22
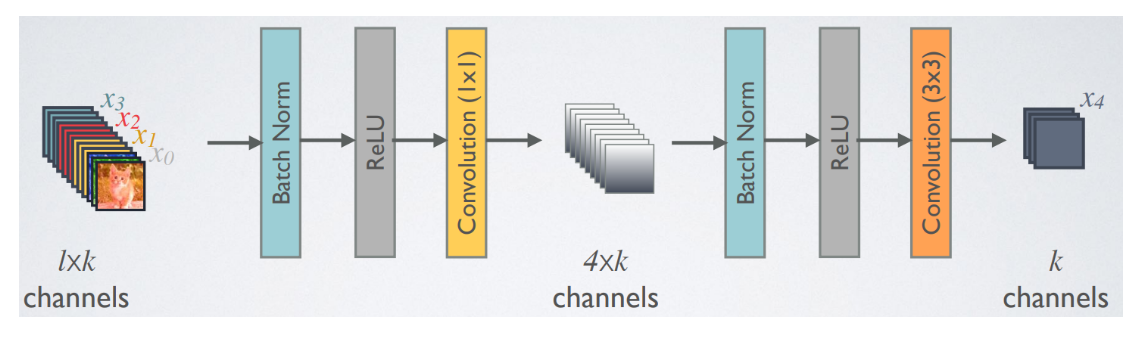
Bottleneck layers
기존의 ResNet의 경우에는 BottleNeck 구조를 만들기 위해 1x1 conv로 차원축소를 한 다음 다시 1x1 conv를 이용해 확장을 한다.
DenseNet의 경우 1x1 conv를 이용해 차원축소을 하지만 확장은 하지 않는다. 이 확장효과는 feature들의 concatenation으로 나타낼 수 있다. 다시 말해, 계산 효율성을 개선하기 위해 3x3 conv 전 bottleneck layer로 1X1 convolution을 도입하여 채널을 줄여주고 이후에 3x3 conv로 weight를 줄여준다.
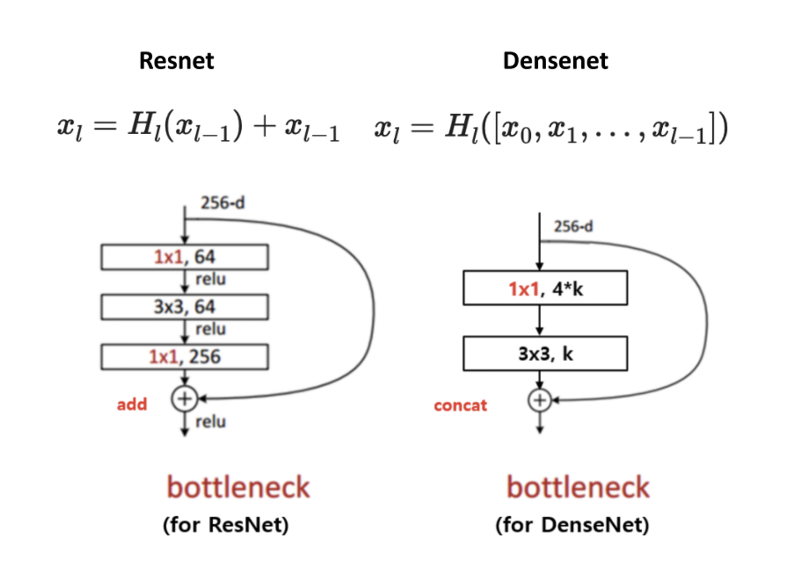
이러한 bottleneck이 도입된 네트워크, $H_{\ell}$의 BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3)를 DenseNet-B라 부른다.
Compression
모델의 압축성를 위해 transition layers에서 특징맵 수를 줄일 수 있는 DenseNet-BC를 사용한다. 만약 하나의 dense block이 m개의 특징맵을 가질 때 다음 transition layer가 $[\theta m]$개의 출력 특징맵을 생성하도록 한다. 여기서 0< $\theta$ ≤ 1 은 압축 인자로, transition layer가 출력하는 채널 수를 조절한다. 논문에서는 $\theta = 0.5$로 설정하여 feature map 개수를 절반으로, 2x2 average pooling에서는 feature map의 size가 절반으로 줄어든다.
DenseNet-C
: $\theta$ < 1 인 DenseNet
DenseNet-BC
: Bottleneck layers & $’\theta < 1’$인 transition layers 모두 사용
Dense connectivity
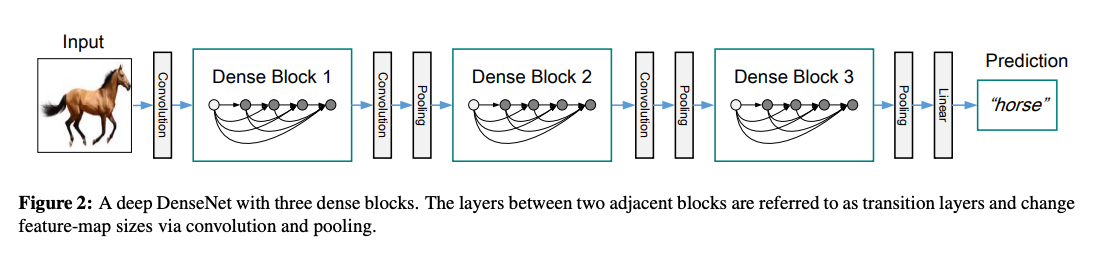 transition layers의 convolution과 pooling을 통해 feature-map의 사이즈와 채널 수를 감소시켜 down-sampling을 진행한다.
transition layers의 convolution과 pooling을 통해 feature-map의 사이즈와 채널 수를 감소시켜 down-sampling을 진행한다.
 위 과정에 bottleneck이 적용이되면 ⇒ BN-ReLU-Conv(1x1)-BN-ReLU-Conv(3x3)이 된다.
위 과정에 bottleneck이 적용이되면 ⇒ BN-ReLU-Conv(1x1)-BN-ReLU-Conv(3x3)이 된다.
Implementation Details
CIFAR / SVHN 데이터셋에서 실험에 사용된 DenseNet은 각각 동일한 층수를 가진 3개의 dense blocks을 가지고 있다.
첫번째 dense block에 들어가기 전에 입력 이미지에 대해 16개(DenseNet-BC의 경우 growth rate 두배) 출력 채널을 가진 convolution이 수행된다.
커널 크기 3x3 convolutional layers에 대해 입력의 각 측면이 1 픽셀씩 제로 패딩되어 특징 맵 크기를 고정한다.
두개의 연속된 dense blocks 사이의 transition layers(전이층)으로는 1x1 합성곱 + 2x2 평균 풀링이 사용되고, 해당 과정으로 특징맵의 사이즈와 채널수가 감소되어 dense block의 feature-map의 크기가 각각 32x32 → 16x16 → 8x8로 변화한다.
마지막 밀집 블록의 끝에서는 global 평균 풀링이 수행되어 그 후 softmax 분류기가 연결된다.
⇒ 논문의 ImageNet 실험에서는 224x224 입력 이미지에 대해 4 dense blocks을 가진 DenseNet-BC 구조를 사용했다. 초기 합성곱 층은 크기 7x7, stride 2의 2k convolutions로 구성되어 다른 모든 층의 feature-maps 역시 k에 따라 결정된다.
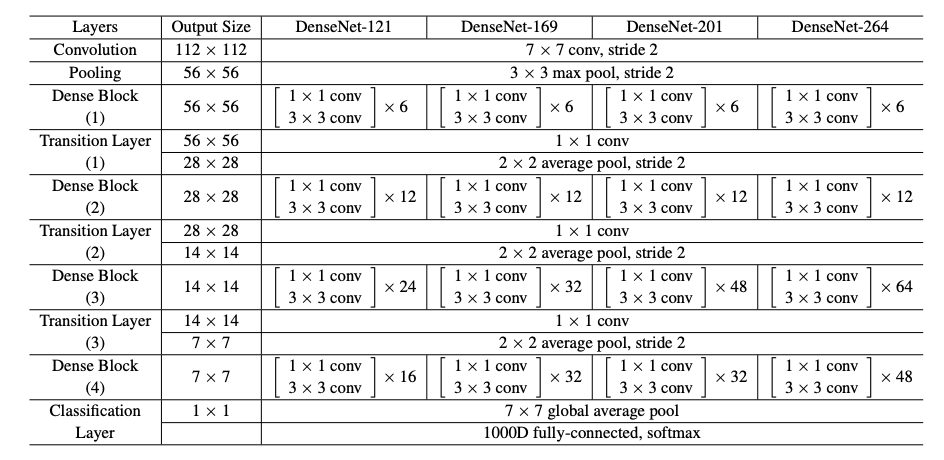 DenseNet architectures for ImageNet: 모든 네트워크의 성장율은 k=32,(densenet-264: k=48) 각 conv층은 BN-ReLU-Conv 순
DenseNet architectures for ImageNet: 모든 네트워크의 성장율은 k=32,(densenet-264: k=48) 각 conv층은 BN-ReLU-Conv 순
Experiments
Datasets & Training
Datasets: CIFAR / SVHN / ImageNet
Optimization: SGD
Batch size: 64(CIFAR&SVHN), 256(ImageNet)
Epoch: 300(CIFAR), 40(SVHN), 90(ImageNet)
Weight decay: $10^{-4}$
Nestrov momentum : 0.9 without dampening
Dropout : 0.2
Classification Results on CIFAR and SVHN
CIFAR, SVHN datasets
k: growth rate / +: standard data augmentation / *: 직접 실행한 결과
각각 동일한 층수를 가진 3개의 dense blocks을 가지며 첫번째 dense block에 들어가기 전에 16개(DenseNet-BC의 경우 growth rate 두배) 출력 채널을 가진 convolution이 수행된다.
커널 크기 3x3 convolutional layers에 대해 입력의 각 측면이 1 pixel씩 zero-padding 되어 특징 맵 크기를 고정한다.
dense blocks 사이에 transition layers에 1x1 cov + 2x2 average pooling이 사용되면 feature-map의 크기는 각각 32x32 → 16x16 → 8x8로 감소하고 마지막 밀집 블록의 끝에서 global 평균 풀링을 진행 후 softmax 분류기가 최종적으로 수행된다.
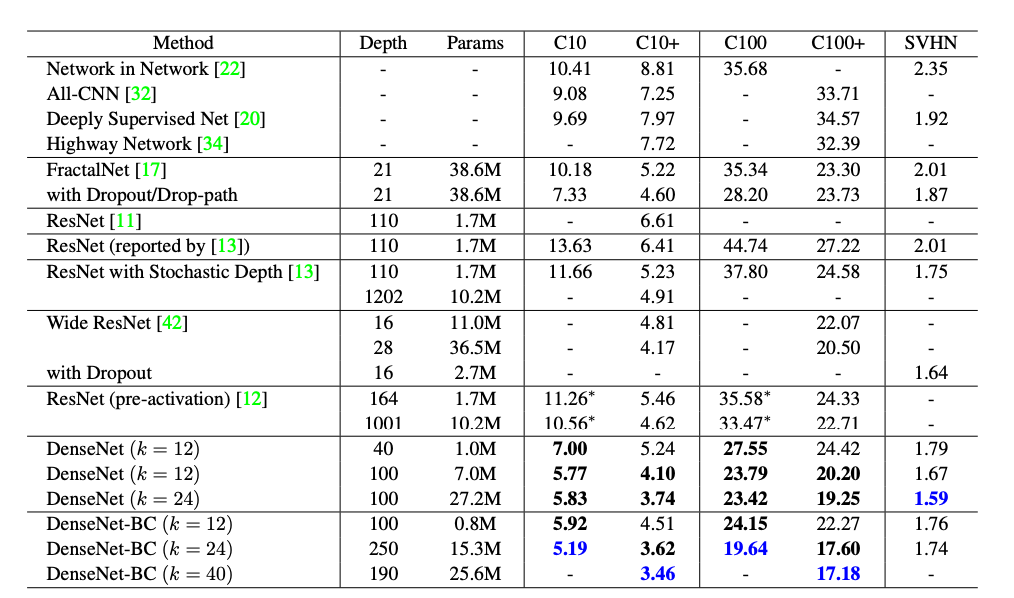 데이터 증강 없는 DenseNet의 모든 결과는 Dropout를 사용하여 얻은 것으로, ResNet보다 더 적은 파라미터를 사용하며 더 낮은 오류율을 보여준다.
데이터 증강 없는 DenseNet의 모든 결과는 Dropout를 사용하여 얻은 것으로, ResNet보다 더 적은 파라미터를 사용하며 더 낮은 오류율을 보여준다.
- Robust in Overfitting & Accuracy
Error Rate
C10: 7.33% → 5.19%, 29% 감소
C10+: 3.46% 달성
C100: 28.20% → 19.64%, 30% 감소
C100+: 17.18% 달성
Capacity
일반적인 DenseNets은 L, k가 증가함에 따라서 모델 용량의 증가에 상응하여 더 나은 성능을 발현한다.
C10+의 경우
Params: 1M → 7M → 27.2M
Error rate: 5.24% → 4.10% → 3.74%
따라서, 더 크고 깊은 모델일 수록 표현력을 잘 활용할 수 있고, 과적합이나 residual networks의 최적화 문제로부터 영향을 받지 않는다는 것을 의미한다.
Parameter Efficiency
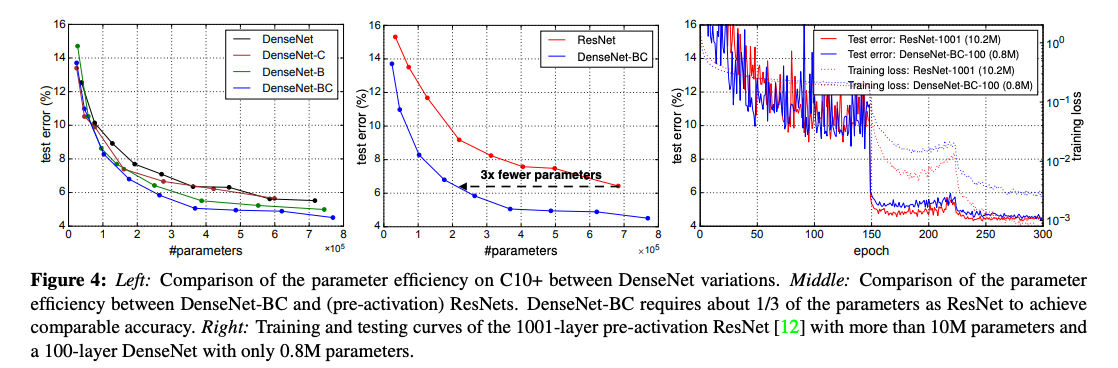
Figure 4의 결과를 보면 ResNets보다 파라미터를 더 효율적으로 활용함을 알 수 있다. bottleneck 구조와 transition layers에서 차원축소를 사용하는 DenseNet-BC는 특히 파라미터 효율성이 뛰어나다.
왼: C10+에서의 DenseNet의 파라미터 효율성
가운데: DenseNet-BC vs pre-activation된 ResNets의 파라미터 효율성 → densenet은 1/3 필요
오: 10M 파라미터의 1001-layer pre-activation ResNet와 0.8M 파라미터의 100-layer DenseNet의 training & testing curves는 유사한 정확도를 나타낸다.
Classification Results on ImageNet
데이터 전처리와 최적화 설정의 차이와 같은 모든 요소를 제거하고 ResNet과 동일한 실험 설정 내에서 단순히 모델만 DenseNet-BC network로 교체해 실험을 진행했다.
논문에서의 실험 설정이 DenseNet에 최적화되지 않고, ResNet에 최적화된 하이퍼파라미터 설정을 사용했다는 점에서 더 광범위한 하이퍼파라미터 연구가 DenseNet의 ImageNet에서의 성능을 더욱 향상시킬 수 있다는 가능성을 보인다.
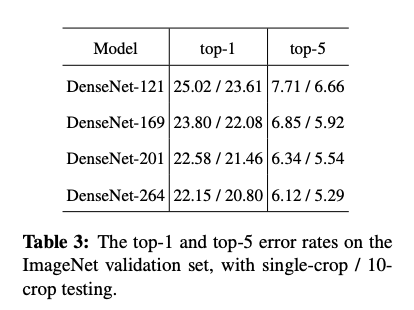 ImageNet에서 DenseNet의 single-crop과 10-crop error rates
ImageNet에서 DenseNet의 single-crop과 10-crop error rates
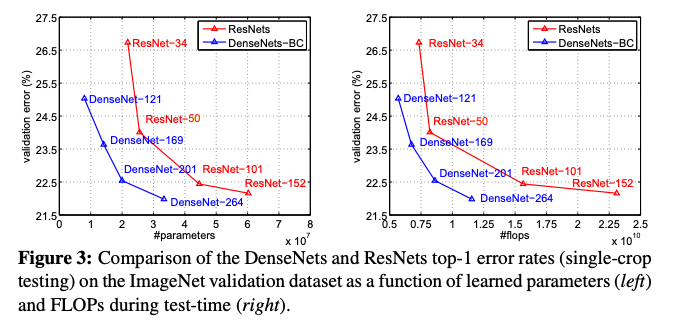 파라미터 수(left)와 FLOPs(right)의 함수로 DenseNet과 ResNet의 single-crop top-1 error rates
파라미터 수(left)와 FLOPs(right)의 함수로 DenseNet과 ResNet의 single-crop top-1 error rates
Discussion
Model compactness
학습된 feature-maps은 이후 모든 층에서 접근할 수 있기 때문에 네트워크 전체에서의 특징 재사용을 허용해 더 compact한 모델을 만든다.
Implicit Deep Supervision
개별 layer들이 짧은 연결을 통해 손실함수로부터 추가적인 supervision을 받기 때문에 일종의 deep supervision을 수행한다.
네트워크 상단의 single classifier가 최대 두세개의 전이층을 통해 모든 층에 직접적인 감독을 제공함에도 불구하고 모든 층이 ‘동일한 loss function’를 공유하기 때문에 손실함수와 기울기는 덜 복잡하게 작용한다.
Feature Reuse
L=40, k=12로 설정된 DenseNet을 C10+에서 훈련시켰을 때 각 블록 내의 합성곱 층에 대해 이전 층과의 연결에 할당된 평균 가중치를 계산했다. 3개의 모든 dense blocks에 대한 히트맵인 Figure 5를 보면 average absolute weight는 합성곱 층이 이전층에 의존하는 정도의 대체지표이다.
따라서, 위치(s, s)에 있는 빨간 점은 ‘층이 평균적으로 이전의 s층들에서 사용된 feature-maps을 강하게 사용한다’를 나타낸다.
- 모든 층이 동일한 블록내에서 많은 입력에 가중치를 분산시킨다. 다시 말해, 매우 초기 층에서 추출된 특징들이 동일한 밀집 블록 내에서 깊은 층에 의해 실제로 direct하게 사용된다.
- 2~3 dense block내 층들은 일관되게 transition layer outputs에 가장 적은 가중치를 할당하며(삼각형 상단), 이는 전이층이 평균적으로 낮은 가중치를 가져 많은 중복된 특징들을 출력한다는 것을 나타낸다.
- 최종 분류 층도 전체 dense block에 거쳐 가중치를 사용하지만, 네트워크 후반부에 더 높은 수준의 특징이 생성될 수 있음을 보인다.
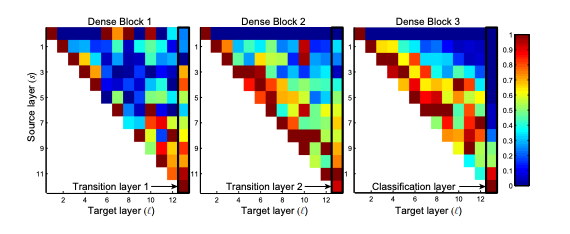 훈련된 DenseNet에서 convolutional layers의 평균 절대 가중치를 나타내는 heat-map으로 첫번째 행은 dense block의 입력층과 연결된 가중치를 나타낸다.
훈련된 DenseNet에서 convolutional layers의 평균 절대 가중치를 나타내는 heat-map으로 첫번째 행은 dense block의 입력층과 연결된 가중치를 나타낸다.
Conclusion
DenseNet은 동일한 feature-map 크기를 가진 모든 층간의 직접적인 연결을 도입했다. 수백개의 층으로 자연스럽게 확장되면서 파라미터 수가 증가함에 따라 일관된 accuracy 향상을 보이며 성능 저하나 overfitting의 문제가 일어나지 않았다.
따라서, 매우 적은 parameter와 간단한 connectivity rule을 따르며 identity mappings, deep supervision, diversified depth 등의 속성을 자연스럽게 통합한다. feature 재사용이 가능하기 때문에 최종적으로 컴팩트하고 정확한 모델을 학습할 수 있게 한다.